A Comprehensive Guide on Understanding Elasticsearch Full-Text Search
Introduction
Elasticsearch has become the de facto standard for implementing powerful full-text search capabilities in applications ranging from e-commerce platforms to content management systems. As a distributed, RESTful search engine built on Apache Lucene, Elasticsearch excels at handling large volumes of data while providing near real-time search capabilities. This article explores the mechanics of Elasticsearch’s full-text search functionality, focusing on index creation, mapping, search templates, and query construction. Furthermore, we’ll discuss some real world implementations of Elasticsearch in e-commerce domain.
The Foundation - Inverted Indices
Before diving into implementation details, it’s important to understand what makes Elasticsearch so efficient. At its core, Elasticsearch uses an inverted index structure, the same technology that powers search engines like Google.
Unlike traditional databases that index records by ID, an inverted index maps terms to the documents containing them. Think of it as the index in the back of a textbook: you look up a term and find all the pages where it appears. This structure allows Elasticsearch to quickly identify which documents contain a search term without scanning every document.

Index Creation
Basic Index Creation
Creating an index in Elasticsearch involves more than just defining a storage location. When you create an index, you’re establishing both the logical namespace and the physical storage characteristics.
PUT /products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}This simple command creates a products index with 3 primary shards and 1 replica per shard, establishing the foundation for our search infrastructure.
Index Templates
Index templates allow you to define settings, mappings, and aliases that should be automatically applied to new indices as they’re created. This is especially useful for time-series data or any case where you create indices regularly.
PUT _index_template/products_template
{
"index_patterns": ["products-*"],
"priority": 1,
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"index.lifecycle.name": "products_policy",
"index.lifecycle.rollover_alias": "products"
},
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"category": {
"type": "keyword"
},
"price": {
"type": "double"
},
"stock": {
"type": "integer"
},
"created_at": {
"type": "date"
},
"updated_at": {
"type": "date"
}
}
},
"aliases": {
"products": {}
}
}
}With this template in place, any new index that matches the pattern products-* will automatically:
- Be configured with 2 shards and 1 replica
- Use the ILM policy called
products_policy - Have the specified mapping for common product fields
- Be added to the “products” alias
Index templates are critical for maintaining consistency across indices and ensuring proper data handling at scale.
Index Mapping
Understanding Mappings
Mappings define how documents and their fields are stored and indexed. Think of mappings as similar to database schemas, but with more flexibility and search-specific features.
Dynamic vs. Explicit Mapping
Elasticsearch offers two approaches to defining field types
- Dynamic mapping: Elasticsearch automatically detects and assigns field types based on the data you index.
- Explicit mapping: You predefine field types before indexing any data.
While dynamic mapping is convenient, explicit mapping provides precise control over how your data is interpreted and indexed. Here’s an example of an explicit mapping.
PUT /products/_mapping
{
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"description": {
"type": "text",
"analyzer": "english"
},
"price": {
"type": "float"
},
"category": {
"type": "keyword"
},
"created_at": {
"type": "date"
}
}
}This mapping defines several field types with specific characteristics
textfields likenameanddescriptionare analyzed and tokenized for full-text search- The
namefield has a multi-field setup with akeywordsub-field for exact matching and aggregations descriptionuses the English analyzer for language-specific processing (stemming, stop words)priceuses afloattype for numeric operationscategoryuses akeywordtype for exact matching and aggregationscreated_atis formatted as adatefor chronological operations
Dynamic Mapping in Detail
When you don’t provide an explicit mapping, Elasticsearch uses dynamic mapping to infer field types. Here’s how it works
- Type Detection Rules
Elasticsearch uses JSON structure to guess field types
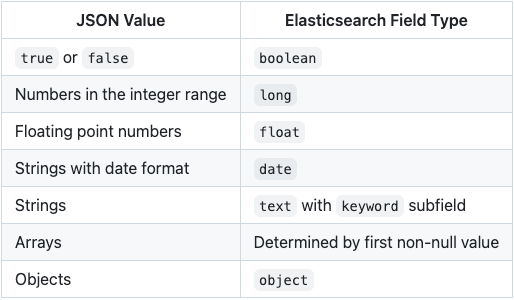
- Dynamic Mapping Example
Let’s see dynamic mapping in action
PUT /dynamic_example/_doc/1
{
"username": "johndoe",
"login_count": 42,
"is_active": true,
"registration_date": "2025-01-15T14:12:00",
"profile": {
"first_name": "John",
"last_name": "Doe",
"age": 35
},
"tags": ["developer", "elasticsearch", "search"]
}After indexing, we can check the mapping Elasticsearch generated
GET /dynamic_example/_mappingThe response would show
username: text field with keyword subfieldlogin_count: longis_active: booleanregistration_date: dateprofile: object with nested mappingstags: text field with keyword subfield
Controlling Dynamic Mapping
You can control dynamic mapping behavior in several ways.
- Dynamic templates : Define custom mapping rules based on field names or data types
PUT /products
{
"mappings": {
"dynamic_templates": [
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
},
{
"location_fields": {
"match": "*_location",
"mapping": {
"type": "geo_point"
}
}
}
]
}
}2. Dynamic setting : Control whether new fields are added automatically
PUT /products
{
"mappings": {
"dynamic": "strict", // Options: true, false, strict
"properties": {
// defined fields here
}
}
}Options include
true: New fields are added to the mapping (default)false: New fields are ignored (not searchable, but still in _source)strict: Reject documents with unknown fields
Dynamic mapping is powerful for rapid development, but explicit mapping gives you more control for production systems.
Analyzers - The Text Processing Pipeline
Full-text search depends heavily on text analysis — the process of converting text into tokens that are added to the inverted index. Analyzers consist of
- Character filters: Pre-process raw text (e.g., strip HTML tags)
- Tokenizers: Split strings into individual tokens (e.g., breaking on whitespace)
- Token filters: Modify tokens (e.g., lowercasing, stemming, synonyms)
You can customize analyzers to fit specific requirements
PUT /products
{
"settings": {
"analysis": {
"analyzer": {
"product_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "asciifolding", "my_synonym_filter"]
}
},
"filter": {
"my_synonym_filter": {
"type": "synonym",
"synonyms": [
"laptop, notebook",
"phone, smartphone, mobile"
]
}
}
}
}
}This custom analyzer would treat “laptop” and “notebook” as equivalent terms during search, improving recall.
Search Templates - Reusable Search Patterns
Search templates provide a way to parameterize and reuse search definitions, separating the query structure from the specific parameters. This is particularly useful for applications with complex search patterns that need to be standardized across multiple components or services.
Creating a Search Template
Templates use Mustache syntax for parameter substitution
POST /_scripts/product_search
{
"script": {
"lang": "mustache",
"source": {
"query": {
"bool": {
"must": {
"multi_match": {
"query": "{{query_text}}",
"fields": ["name^2", "description"]
}
},
"filter": [
{{#price_range}}
{
"range": {
"price": {
"gte": "{{min_price}}",
"lte": "{{max_price}}"
}
}
},
{{/price_range}}
{{#category}}
{
"term": {
"category": "{{category}}"
}
}
{{/category}}
]
}
},
"size": "{{size}}",
"from": "{{from}}"
}
}
}Using a Search Template
With the template stored, you can execute searches by providing just the parameters
POST /products/_search/template
{
"id": "product_search",
"params": {
"query_text": "wireless headphones",
"price_range": true,
"min_price": 50,
"max_price": 200,
"category": "electronics",
"size": 10,
"from": 0
}
}Templates offer several benefits
- Centralized query logic
- Simplified application code
- Easier testing and optimization
- Version control for search behavior
- Security through separation of query structure and user input
Search Queries - The Query DSL
Elasticsearch’s Query DSL (Domain Specific Language) provides a rich vocabulary for expressing search intent. Let’s explore key query types for full-text search.
Full-Text Queries
Match Query
The most basic full-text query tokenizes the input and finds documents with matching terms
GET /products/_search
{
"query": {
"match": {
"description": "wireless bluetooth headphones"
}
}
}This query will find documents where the description contains any of the terms “wireless,” “bluetooth,” or “headphones.”
Multi-Match Query
Search across multiple fields with different weights:
GET /products/_search
{
"query": {
"multi_match": {
"query": "wireless headphones",
"fields": ["name^3", "description^2", "tags"],
"type": "best_fields"
}
}
}The ^ notation indicates field boosting—matches in the name field will contribute more to the relevance score than matches in description or tags.
Query String Query
For advanced users who need a more expressive syntax:
GET /products/_search
{
"query": {
"query_string": {
"default_field": "description",
"query": "wireless AND (noise AND cancelling OR anc) -wired"
}
}
}This powerful query syntax allows boolean operators, grouping, and exclusions, similar to what you might use in a search engine.
Compound Queries
Real-world searches often combine multiple criteria. The bool query lets you compose complex queries from simpler ones.
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "headphones" } }
],
"should": [
{ "match": { "description": "wireless" } },
{ "match": { "description": "bluetooth" } }
],
"must_not": [
{ "match": { "description": "wired" } }
],
"filter": [
{ "range": { "price": { "lte": 200 } } },
{ "term": { "in_stock": true } }
]
}
}
}This query demonstrates the four boolean clauses
must: Required matches that contribute to scoreshould: Optional matches that contribute to scoremust_not: Documents with these matches are excludedfilter: Required matches that don't contribute to score (more efficient)
Boosting Techniques for Relevance Tuning
Boosting is a critical concept in full-text search that allows you to influence which documents are considered most relevant. Elasticsearch offers several boosting techniques:
1. Field Boosting
Field boosting increases the importance of matches in specific fields
GET /products/_search
{
"query": {
"multi_match": {
"query": "bluetooth headphones",
"fields": [
"title^3",
"product_name^2.5",
"description",
"tags^0.5"
]
}
}
}In this example, matches in the title field are three times more important than matches in the description field.
2. Term Boosting
Term boosting increases the importance of specific terms in a query
GET /products/_search
{
"query": {
"query_string": {
"fields": ["title", "description"],
"query": "bluetooth^2 wireless headphones noise^1.5 cancelling"
}
}
}Here, documents containing “bluetooth” and “noise” will rank higher than those with equal matches of other terms.
3. Document Boosting with Function Scores
For more complex boosting based on document attributes:
GET /products/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "wireless headphones",
"fields": ["title", "description"]
}
},
"functions": [
{
"field_value_factor": {
"field": "average_rating",
"factor": 1.2,
"modifier": "sqrt",
"missing": 1
}
},
{
"filter": { "term": { "featured": true } },
"weight": 1.5
},
{
"gauss": {
"release_date": {
"origin": "now",
"scale": "365d",
"decay": 0.5
}
}
}
],
"score_mode": "multiply",
"boost_mode": "multiply"
}
}
}This advanced example:
- Uses
field_value_factorto boost by rating (with square root modifier) - Applies a fixed boost to featured products
- Uses a decay function to gradually reduce scores for older products
4. Context-Aware Boosting with Rescore Queries
For performance-efficient boosting, you can use a lightweight query first, then apply more complex scoring to the top results:
GET /products/_search
{
"query": {
"match": {
"description": "wireless headphones"
}
},
"rescore": {
"window_size": 100,
"query": {
"rescore_query": {
"bool": {
"should": [
{ "term": { "brand": { "value": "sony", "boost": 1.5 } } },
{ "term": { "brand": { "value": "bose", "boost": 1.4 } } },
{ "range": { "sales_rank": { "lte": 100, "boost": 2.0 } } }
]
}
},
"query_weight": 0.7,
"rescore_query_weight": 0.3
}
}
}This technique applies brand and popularity boosts only to the top 100 results from the initial query, balancing between relevance and performance.
Boosting Best Practices
- Test extensively: Boosting requires iteration and user feedback
- Use the Ranking Evaluation API to quantify relevance improvements
- Start with conservative boosts (1–3x) and adjust gradually
- Consider domain-specific factors that indicate quality or relevance
- Document your boosting strategy to maintain consistency
Relevance Scoring
Understanding how Elasticsearch scores results is crucial for optimizing search relevance. By default, Elasticsearch uses the BM25 algorithm, which considers:
- Term frequency (TF): How often a term appears in a document
- Inverse document frequency (IDF): Terms that appear in fewer documents get higher weight
- Field length normalization: Matches in shorter fields get higher weight
For specialized use cases, you can influence scoring through:
- Field boosting
- Function scores based on numeric values
- Decay functions for location, dates, or numeric values
Optimizing Full-Text Search
After setting up your indices and queries, consider these optimization techniques:
- Use field data types appropriately:
keywordfor exact matches,textfor analyzed content - Create field aliases: Simplify complex mappings for clients
- Consider index-time vs. search-time analysis: Some operations are more efficient at index time
- Implement proper caching strategies: Especially for frequently used filters
- Monitor and tune shard and replica counts: Based on your data volume and query patterns
Conclusion
Elasticsearch’s full-text search capabilities provide a powerful foundation for building search-intensive applications. By understanding index creation and mapping, search templates, and the query DSL, you can leverage Elasticsearch to its full potential.
The key to success lies in designing your indices with both search performance and relevance in mind. Start with explicit mappings that reflect your data structure, use search templates to standardize complex queries, and combine different query types to achieve the precise search behavior your application requires.
As your application grows, continue to iterate on your search implementation, measuring both performance metrics and relevance to ensure your users can quickly find what they’re looking for.
Happy Learning !!!
